 010-65363526
010-65363526 rmzk001@163.com
rmzk001@163.com

近日,清华大学智能产业研究院(AIR)研究团队在自动驾驶与具身智能交叉领域取得重要研究进展。团队提出了一种名为“具身认知增强的端到端自动驾驶”的新范式,首次将人类驾驶员的脑电信号(EEG)认知特征融入自动驾驶模型训练,在不增加车载硬件成本的前提下,显著提升了自动驾驶系统在复杂环境下的规划能力与安全性。相关成果已被国际人工智能顶级会议NeurIPS 2025接收。
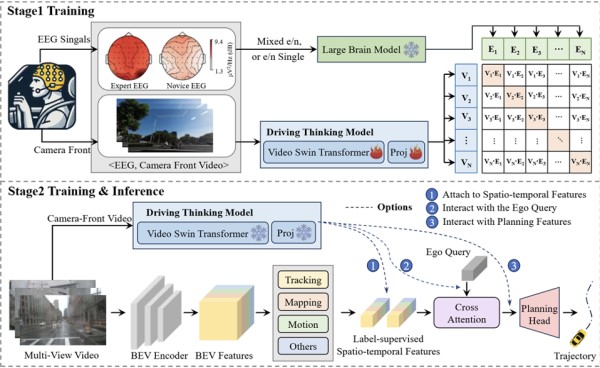
当前,以视觉为基础的端到端自动驾驶技术已成为行业发展的新趋势。然而,主流模型大多依赖于对道路、车辆等视觉特征的标签监督训练,难以像人类大脑一样进行具身推理,导致模型在应对突发状况和复杂场景时的泛化能力受限。如何让自动驾驶系统具备人类驾驶员的“直觉”与认知能力,是当前学术界和工业界关注的难点。
针对这一痛点,清华大学团队提出了一种创新的“驾驶-思考”(Driving-Thinking)训练框架。研究团队采集了包含视频与驾驶员脑电信号的多模态数据集,并利用通用脑电大模型(LaBraM)提取人类驾驶过程中的潜在认知特征。通过对比学习技术,研究人员让自动驾驶的视觉网络在训练阶段“模仿”人类大脑对交通环境的认知反应。
该研究的最大亮点在于其独特的两阶段训练策略。在第一阶段,模型利用脑电数据进行跨模态学习,获取驾驶认知能力;在第二阶段及实际应用中,系统仅需输入常规的车载摄像头视频数据,即可利用已习得的认知能力辅助驾驶决策,无需在车端部署脑电采集设备。这种“以脑教眼”的方式,实现了人类隐性认知知识向机器视觉模型的有效迁移。
实验数据显示,该技术在公开的自动驾驶数据集nuScenes以及闭环仿真测试平台Bench2Drive上均表现优异。在引入人类认知特征后,主流端到端自动驾驶模型(如UniAD、VAD)的规划轨迹误差显著降低,碰撞率相对下降了约18%至26%。特别是在前车突然切入等高风险场景下,增强后的模型展现出了类似人类驾驶员的防御性驾驶策略,有效避免了事故发生。
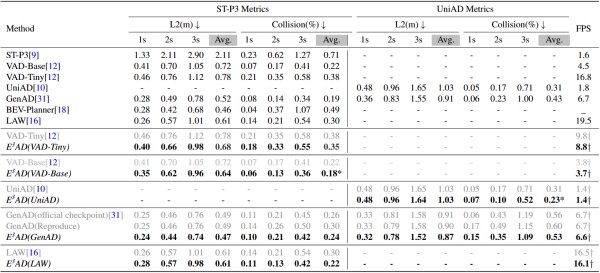
研究团队表示,这是业内首次尝试将人类驾驶认知直接用于增强端到端自动驾驶规划任务。该成果不仅为提升自动驾驶安全性提供了新思路,也为未来脑启发式人工智能系统(Brain-inspired AI)与具身智能的发展提供了重要的理论与实践参考。
(责编:张若涵)

